如何让 AI 真正做好数据分析?
最近我一直在琢磨一个问题:AI 都这么强了,为什么让它做数据分析,出来的东西总差点意思? 我和 AI 做了好几轮深度对谈,把这个问题翻来覆去地拆了一遍。结论有点反直觉——问题不在模型能力,而在一些更本质的东西。这篇文章就是把这些思考整理出来,希望对同样在折腾 AI + 数据分析的朋友有点启发。
先说结论:AI 做数据分析,到底卡在哪?
如果你直接把一个分析命题丢给 AI,比如”帮我看看 Q1 的留存为什么掉了”,即使是当前最强的模型,大概率也交不出让你满意的答案。
不是它不聪明,而是它根本不知道你在问什么。
这话听起来有点绝对,但仔细想想——数据分析本质上不是一个”生成任务”,而是一个”决策支持任务”。它的终极目的是降低决策的不确定性。要做好这件事,光会写 SQL、会画图表远远不够,AI 还得知道:你是谁、你要做什么决策、你关心什么粒度的信息、这个结论谁来负责。
这些东西,模型的预训练数据里一个字都没有。
四层难点:比想象的要深
我把 AI 做数据分析的难点拆成了四层,越往下越扎心。
第一层:AI 不知道”你到底想分析什么”
领导说一句”看看留存怎么样”,一个老练的分析师脑子里瞬间会闪过一串问题:谁要看?为什么现在看?是要做汇报还是要做决策?关心整体还是某个渠道?要挖多深?
这些问题的答案,决定了分析怎么做。但这些答案全都是隐性的——它藏在你对业务节奏的理解里,藏在你和领导上周的一次聊天里,藏在你对团队 KPI 的判断里。
AI 统统不知道。
所以它要么给你一个面面俱到但毫无重点的”全家桶分析”,要么给你一个看起来专业但完全没回答到点子上的报告。两种都让人头疼。
更要命的是,有些分析是有组织政治敏感性的。比如某个团队的指标不好看,人类分析师会巧妙调整呈现方式,AI 完全没有这层意识——它可能直接把最难看的数据怼在第一页。
第二层:企业数据的”暗知识”太多

假设 AI 搞清楚了要分析什么(虽然很难),接下来它要取数。这一步同样是地雷阵。
企业数据不像公开数据集那么规整。“DAU”这个词,在不同业务线可能有完全不同的定义;同一张表的同一个字段,去年和今年的口径可能已经变了;有些数据是 T+1 的,有些是实时的;有些表看起来能 join,但时间窗口对不上。
这些”暗知识”散落在各种文档里,散落在老员工的脑子里,散落在某个群聊的某条消息里。AI 哪怕把整个数仓的 schema 看一遍,也搞不定这些。
最隐蔽的坑是:AI 算出来的数字看起来”合理”,但其实是错的。你不仔细核对根本发现不了。
第三层:没人敢为 AI 的结论负责
这是最容易被忽略但最致命的问题。
AI 不承担任何错误后果。如果它的分析结论导致了一个错误的业务决策,谁来负责?答案是——看这份报告并且签字确认的那个人。
但问题是,如果分析师看不透 AI 的分析过程(用了什么数据、做了什么假设、选了什么口径),他怎么敢签字?怎么敢在周会上把 AI 的结论当自己的结论讲出来?
信任不是喊出来的,是靠一次次验证建立的。初期用户会逐行核对 AI 的每个数字,后期可能只抽查关键节点。产品必须支持这种”信任度逐步上升”的使用模式。
第四层:AI 会写报告,但不解决问题
AI 写流畅的文本是强项,但数据分析的最终交付物不是一篇漂亮的文章,而是决策建议。
好的分析师会把技术语言翻译成业务语言,会预判领导的追问提前准备好 drill-down,会明确区分”我们确定的”和”我们猜测的”,最终给出带优先级的 action items。
AI 产出的报告呢?通常是”看起来很专业但不解决问题”——数据都对,图表都漂亮,但你看完之后还是不知道该干嘛。
两个根因:把问题想透
把上面四层难点翻来覆去想了几遍之后,我觉得可以归结为两个根因:
第一,隐性知识没有显性化。
决策上下文(为谁分析、服务什么决策)、数据暗知识(指标口径、表关系、数据潜规则)、受众认知(决策者的偏好和关注点)——这些知识全都是隐性的、动态的、组织特有的。它们不是 AI 通过预训练能获得的通用知识,必须通过某种机制”喂”给 AI。
第二,责任机制没有建立。
AI 不负责,人没信息。解决这个矛盾不是靠”让 AI 更准”(这在短期内不现实),而是靠让人能快速、低成本地验证 AI 的产出。
一句话总结:隐性知识的缺失让 AI 难以做对,责任机制的缺位让人难以信任。 这两个根因加在一起,才是 AI 做数据分析最大的障碍。
这也意味着,突破口不在”调模型”,而在”建基础设施”——把隐性知识变成 AI 可消费的结构化资产,把分析过程变成人可审计的透明链路。
我的方案构想:一个”会成长”的分析画布
想清楚问题之后,我脑子里逐渐浮现出一个产品形态。它有一个核心设计理念:产品不”升级”,而是”成长”。
什么意思呢?从第一天起,产品的交互框架就是终态。变化的不是界面,而是每个环节上”AI 自己干”和”等人确认”的比例——用的人越多、积累的知识越多,AI 能自主完成的就越多。人的参与度下降不是产品强制的,而是用户基于信任主动放手的。
为什么是”画布”而不是”对话框”?
我认真对比过三种形态:
| 形态 | 好处 | 致命伤 |
|---|---|---|
| 纯对话(ChatBI) | 上手简单 | 过程不可见、出错要从头来、没法审计 |
| 传统 BI 看板 | 结构化强 | 不灵活,只能看预设的维度 |
| 分析画布 + Chat | 过程透明、可分叉、可审计 | 上手成本稍高(但目标用户是分析师,OK的) |
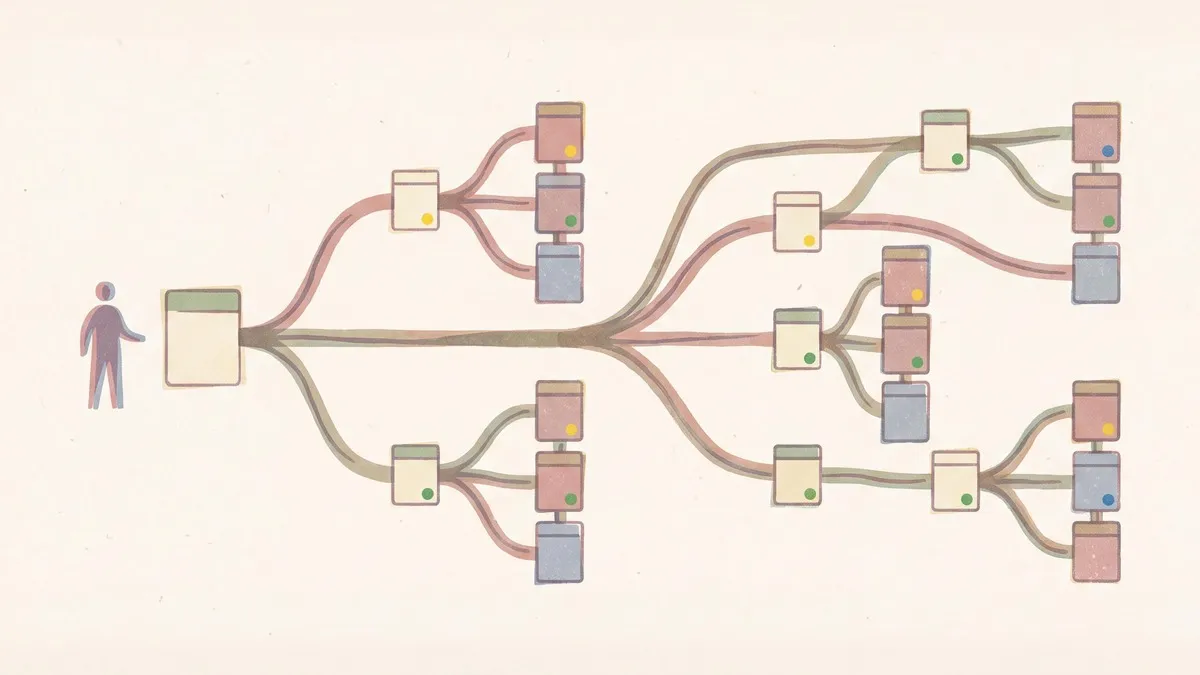
画布的核心隐喻是一棵分析树——从命题出发,拆解为子问题,每个子问题对应”取数→分析→结论”的链路,最终汇聚为综合结论。树上的每个节点都是一张可交互的卡片,用颜色标记状态:🟡 AI 草稿、🟢 人已确认、🔵 人已修改。
理想情况下,随着时间推移,画布上的黄色越来越少,绿色越来越多。这本身就是人机协作在进化的可视化证据。
五个让这件事成立的核心机制
光有画布不够,我设计了五个互相咬合的机制来解决前面提到的两个根因。
机制一:结构化 Brief——把”模糊需求”变成”清晰任务”。
每次分析的第一步不是开干,而是先填一张 Brief:谁要看、什么场景、关注哪些指标、要挖多深、是否敏感。初期人填、AI 补全建议;后期 AI 根据历史模式自动生成,人只需扫一眼确认。每次 Brief 的填写和修改自动沉淀,下次类似命题 AI 直接调取历史模板。
机制二:活的数据语义层——让”暗知识”在使用中自然生长。
这不是传统那种写完就没人维护的数据字典,而是一个用→问→记的活循环:AI 取数时先查语义层;查不到就发起结构化追问(不是空泛的”请确认”,而是给出具体选项和历史统计);用户回答后自动写入语义层,下次不再追问。用得越多,追问越少,AI 越自主。
机制三:X 光模式——让每一步都能被”透视”。
每张卡片都支持渐进式展开。L1 一句话摘要(快速判断合理性),L2 分析逻辑(为什么选这个方法),L3 底层数据(SQL、中间表),L4 自动校验结果。用户根据自己当前的信任程度选择看多深。分享结论时,不是分享一张图,而是分享整棵分析树的只读快照——接收者可以自己展开 X 光查看完整链路。
机制四:置信度系统——让”该不该人工审”有据可依。
每个结论卡片都有一个置信度分数,基于口径匹配度、数据质量、方法成熟度、历史验证度来计算。高置信度自动通过,中等的等用户确认,低的强制人工审核。关键是阈值用户可调——信任度高的老用户可以把”自动通过”的门槛调低。这就是”产品形态不变,人的参与自然减少”的核心引擎。
机制五:反馈飞轮——每次人的修改都让系统变聪明。
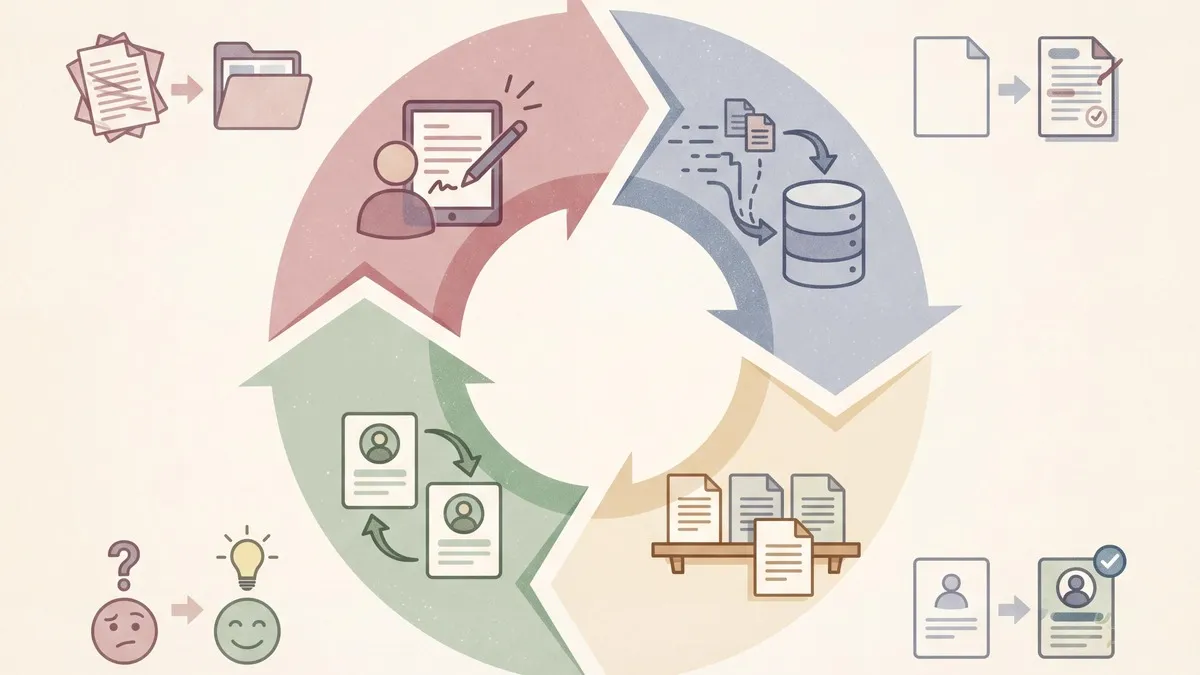
人改了 Brief,沉淀到场景库;改了 SQL,沉淀到语义层;改了分析方法,沉淀到模板库;改了结论措辞,沉淀到受众画像库。用户连续 N 次确认同类型卡片无修改,该类型的自动通过阈值就自动降低。每次分析完成后还会自动生成复盘卡片——对比 AI 初版和人修改后的终版,高亮差异,帮系统持续学习。
人机比例会怎么演进?
如果上面这些机制都跑起来了,我大致估了一下人机比例的变化趋势:
| 阶段 | 时间 | 人工参与度 | 状态描述 |
|---|---|---|---|
| 冷启动 | 0-1 月 | ~80% | AI 主要打下手,人全程把关 |
| 知识积累 | 1-2 月 | ~50% | 飞轮转起来,常规分析 AI 基本能搞定 |
| 信任建立 | 2-3 月 | ~25% | AI 主导大部分分析,人只审关键节点 |
| 成熟期 | 3 月+ | ~12% | AI 是分析中枢,人只在新场景和重大决策时介入 |
从 80% 降到 12%,靠的不是模型升级,而是知识积累和信任建立。这才是我觉得最有意思的地方。
写在最后
回到最初那个问题——如何让 AI 做好数据分析?
我的答案可能和很多人的直觉不一样:重点不是让模型更聪明,而是帮它补上它天然缺失的两样东西——组织的隐性知识,和人机之间的信任机制。
前者让 AI 有可能做对,后者让人有勇气信任它。两件事都需要时间来”养”,不是上线第一天就能解决的。这也是为什么我把这个产品叫做”会成长的分析画布”——它不是一个静态的工具,而是一个和用户共同进化的系统。
说到底,人和 AI 做数据分析的理想关系,不是”替代”,也不应该停留在”辅助”。它应该是一种渐进的共生——AI 在使用中学习组织的知识,人在验证中建立对 AI 的信任,两边螺旋上升,最终到达一个人单独做到不了、AI 单独也做不到的地方。
那个地方,才是 AI Native 数据分析真正的样子。
本文基于作者与 AI 的多轮对谈整理而成。文中的产品方案是概念性思考,旨在提供一种看待 AI + 数据分析的新角度。如果你也在做类似的事情,欢迎交流。